
Rich Site Summary (RSS) is not quite state-of-art technology but thanks to its simplicity RSS feeds are still useful nowadays.
In this post I’ll show you how you can parse websites and provide your own RSS feed with Spring Boot and few useful libraries such as JSoup and ROME.
Please note: This post isn’t a step-by-step tutorial. The source code with fully working example can be found on GitHub.
The goal
The main reason for creation of this simple example was the need for news subscription from specific multiple sites.
All of them were based on the same CMS but they didn’t provide any RSS feed nor API. In order to watch changes on these websites I decided to provide this simple proof-of-concept which will be integrated in the larger application in the future.
The goal is to parse multiple websites (for example once a day) and store all obtained news entries in the database. Persisted news entries are then used for providing RSS feed endpoint.
Then, for example, this RSS feed can be consumed in your favourite reader (such as Feedly or Inoreader).
Technology
In this example I used Spring Boot as a web framework and PostgreSQL as a database engine.
Furthermore, following libraries was used:
- JSoup – for HTML parsing
- ROME – for RSS feed generation
- Lombok – for limit boilerplate code
Parsing rules
First of all we have to define rules for parsing the website. In other words we have to ‘tell’ JSoup what exactly are we looking for on the specific website.
For this purpose I created a class called ParseEntryRule which defines selectors for JSoup. Basically, we need selectors (which means for example CSS class or id selectors) for single news container, its title, content excerpt and URL.
For more information please read about JSoup selector syntax.
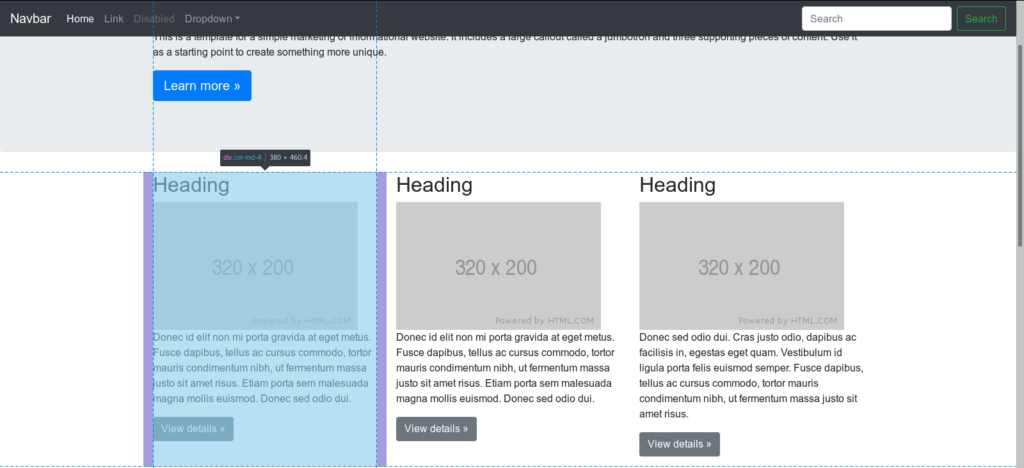
Please take a look at this example Bootstrap news website.
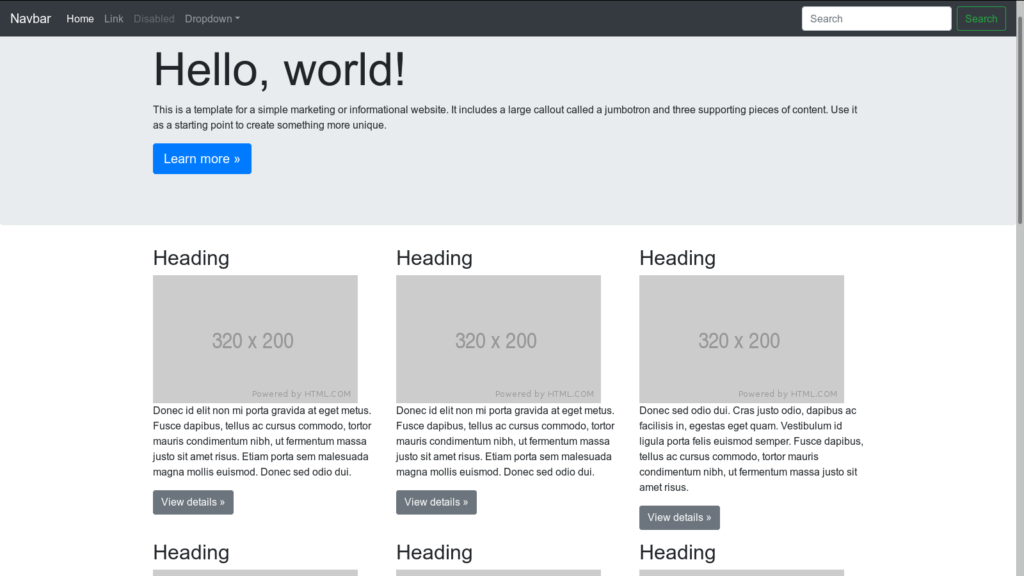
Now, we have to figure out the parsing rule here. Let’s take a look at HTML source code.
Let’s start from news title selector which is .news-title here.
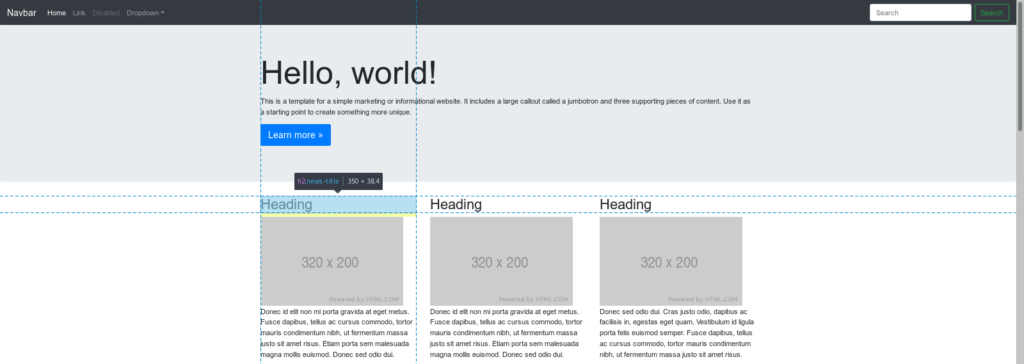
Content (news excerpt) selector in this case is .news-content.
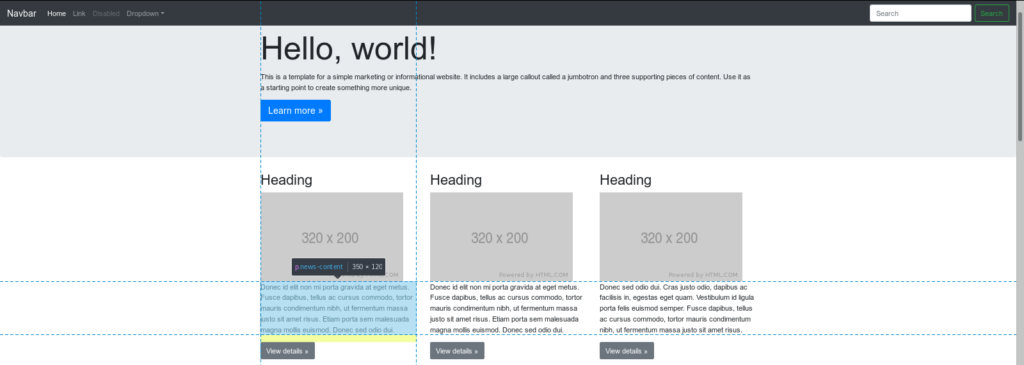
Link is a button type so we aim at .btn-secondary.
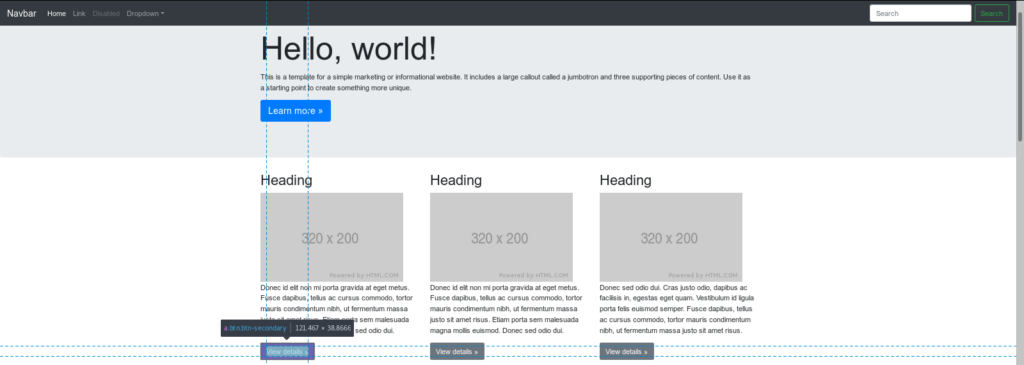
The one remaining parameter which is newsContainer is basically a repeatable HTML element which contains single news entry. In our case it’s div element with col-md-4 class. So the value will be simply .col-md-4 here.
Rules (ParseEntryRule) are linked with TargetWebsite class which besides specific rule contains target website URL.
After we have our rules defined and linked with specific websites we can start scrap them using JSoup.
Web scraping
During website parsing, JSoup recognizes news element by given rules and then we would like to save it in the database.
For this purpose I created another entity class called FeedEntry from which we’ll generate RSS feed in the next steps.
@Builder, @AllArgsConstructor, @NoArgsConstructor and previously used @Data are all Lombok annotations which helps us limit boilerplate code.
As we didn’t define any rule for thumbnail image, the parser takes the src attribute value of first img found in selected element.
Create RSS feed
As I mentioned before the RSS feed is created using news entities stored in database.
There are two methods provided by our REST controller RssFeedController:
/rss for general RSS feed and /rss/<TARGET_WEBSITE_ID> for dedicated feed with single website news entries.
How does it work under the hood? Let’s take a look at RssGeneratorService class.
In this service class we’re working with ROME library for RSS feed generation. SyndFeed is a general RSS feed object and it contains SyndEntry class objects which are single feed entries.
@Log and @SneakyThrows are both another Lombok annotations. The former provides a logger object in our class, the latter is used for catching exceptions.
The FeedEntryService is basically a wrapper for Spring Data repository.
The output is a String object containing RSS feed in XML format.
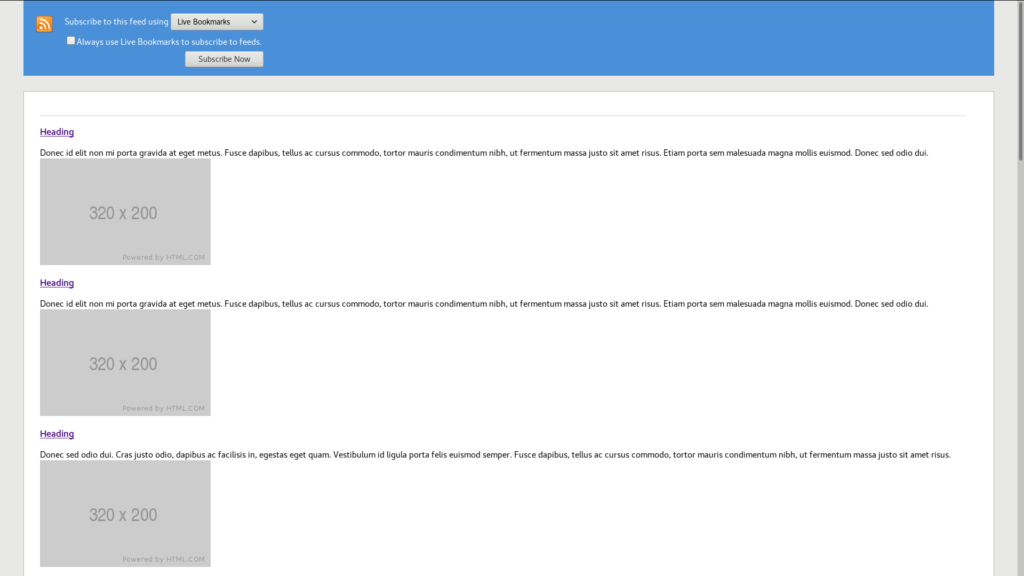
The result of example feed response rendered in Firefox:
Summary
Provided example covers simple news websites scraping and RSS feed generating using Spring Boot with some external libraries. Please note that it applies only to the typical news/announcements websites.
If you would like to do more complex scraping you should definitely try another approach. You should also consider to make it more stable and error-proof by connection retry implementation or more advanced HTML parsing.
Please also note that entries in feed are not sorted in chronological order when it comes to provide a general feed.
The source code is available on GitHub.
Have fun!